Dear Professor,
I have a couple of questions about the Jordan canonical form section of the course if you get a spare moment.
1. I understand that if are considering linear maps from a vector space over the complex numbers to another vector space over the complex numbers, then eigenvalues always exist. When we find a Jordan basis, we use these eigenvalues. Does this mean we are assuming that the field in question is the complex numbers? Surely if not, then these eigenvalues aren’t guaranteed to exist so we can’t always find a Jordan basis?
2. After finding a pre-Jordan basis, we have to replace some basis vectors so as to satisfy the condition that if 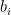 belongs to
belongs to  , then
, then  belongs to
belongs to  for
for 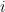 greater than 1. I have noticed that sometimes there is a choice as to which basis vector in to replace. Does it matter? Is there a convention? Similarly, when extending our basis
greater than 1. I have noticed that sometimes there is a choice as to which basis vector in to replace. Does it matter? Is there a convention? Similarly, when extending our basis

for
to be a basis for , there may be a choice as to which basis vector we choose to add. Does it matter? Is there a convention? My questions above lead me to believe that there are actually infinitely many Jordan bases for any one linear map / matrix, but that their Jordan canonical form is unique up to permutation of the Jordan blocks. Am I correct in thinking this?
3. Finally, say we have a linear map with two eigenvalues,  and
and  Say the characteristic polynomial is
Say the characteristic polynomial is

and the minimal polynomial is

with, obviously,  less than or equal to
less than or equal to  ,
,  less than or equal to
less than or equal to  . I don’t understand how we know without proof that
. I don’t understand how we know without proof that  . I have chosen a two eigenvalue case for simplicity – obviously I’m interested in all several eigenvalue cases.
. I have chosen a two eigenvalue case for simplicity – obviously I’m interested in all several eigenvalue cases.
Thanks very much!
Reply:
1. You are right that that eigenvalues need to be contained in the field of definition for a linear map to admit a Jordan canonical form. For example, the rotation matrix

will not have a Jordan canonical forms over  . Over
. Over  , however, it is diagonalizable, and the diagonal form *is* the Jordan canonical form. (What is it?)
, however, it is diagonalizable, and the diagonal form *is* the Jordan canonical form. (What is it?)
2. There is an error in the condition you write, which could be minor or serious. To be a Jordan basis for a linear map  with one eigenvalue
with one eigenvalue  , the requirement is that
, the requirement is that

for  . Look carefully to see and understand the difference from what you wrote. (Actually, from the overall understanding reflected in your message, I suspect your mistake was just a misprint. But I wrote the above for the general reader.)
. Look carefully to see and understand the difference from what you wrote. (Actually, from the overall understanding reflected in your message, I suspect your mistake was just a misprint. But I wrote the above for the general reader.)
As to your question, you are write there there are many choices involved. This is the point people often find confusing, not just in this topic, but in many basic mathematical problems: when there is not a unique solution. We just have to understand the material well enough to feel relaxed about the choices. There is no general convention I can think of regarding `good’ choices, other than obvious demands of economy like simple numbers and as many zero entries as possible.
All of your remaining observations are correct. I wouldn’t be too surprised if a study of the *space of all possible Jordan bases* would yield some insight on good choices, at least in some natural special situations.
3. The general discussion is an obvious generalization of the case with two eigenvalues, so let’s stick to your question as it stands.
For  , we have
, we have

and hence,

Therefore,  is stabilized (that is, taken to itself) by . Similarly,
is stabilized (that is, taken to itself) by . Similarly,  is stabilized by . By considering the shape of the Jordan canonical form for
is stabilized by . By considering the shape of the Jordan canonical form for

(the one eigenvalue case) we see that

for  . Similarly,
. Similarly,

for  . But we have
. But we have

by the primary decomposition theorem. So

or

Therefore,

and
 .
.
 be the real vector space of all functions from the natural numbers to the reals. Then
be the real vector space of all functions from the natural numbers to the reals. Then  has uncountable dimension. To see this, for each
has uncountable dimension. To see this, for each  , let
, let 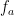 be the function such that
be the function such that  .
. are linearly independent.
are linearly independent. with a strictly increasing sequence of
with a strictly increasing sequence of 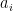 are linearly independent.
are linearly independent. , the fact being clear for
, the fact being clear for 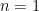 . Suppose
. Suppose  with
with  . The equation means
. The equation means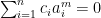
 . Thus,
. Thus,  for all
for all  . This shows that
. This shows that  . Thus, by induction, all
. Thus, by induction, all  .
. be a basis for
be a basis for  of indices such that
of indices such that  . The linear span of any given finite set of the
. The linear span of any given finite set of the  is finite-dimensional. Hence, for any finite subset
is finite-dimensional. Hence, for any finite subset  , there are at most finitely many
, there are at most finitely many  . That is, the map
. That is, the map  is a finite-to-one map from the positive reals
is a finite-to-one map from the positive reals  to the finite subsets of
to the finite subsets of  . Hence, the set of finite subsets of
. Hence, the set of finite subsets of ![R[x]](https://s0.wp.com/latex.php?latex=R%5Bx%5D&bg=ffffff&fg=000&s=0&c=20201002) . This is perhaps the first example you’ve seen where you can prove that two vector spaces of *infinite* dimensions are not isomorphic by simply counting the dimensions and comparing them.
. This is perhaps the first example you’ve seen where you can prove that two vector spaces of *infinite* dimensions are not isomorphic by simply counting the dimensions and comparing them.

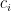 have to be zero. This does require proof. One quick way to do this is to note that all polynomial functions are differentiable. And if
have to be zero. This does require proof. One quick way to do this is to note that all polynomial functions are differentiable. And if

 . But
. But  Thus,
Thus,  that has *finite support* in that
that has *finite support* in that  for all but finitely many
for all but finitely many  becomes identified with the function
becomes identified with the function 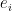 that sends
that sends  and
and  as functions from
as functions from  to
to 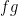 ?
?




 and
and 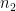 , for example, using a column expansion. [A word on induction: I’m sure you can see these identities right away by now and you might not need to write down the inductive proof explicitly. But even so, since you’re essentially beginning mathematics, it’s good to be aware that a careful proof of something of this sort often requires induction.]
, for example, using a column expansion. [A word on induction: I’m sure you can see these identities right away by now and you might not need to write down the inductive proof explicitly. But even so, since you’re essentially beginning mathematics, it’s good to be aware that a careful proof of something of this sort often requires induction.] iff the rows of
iff the rows of  are linearly independent iff the columns of
are linearly independent iff the columns of 
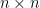 matrix
matrix 



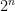 terms. Now try to collect those terms in powers of
terms. Now try to collect those terms in powers of  , and you will find
, and you will find 
 minors emerging naturally. The only subtle point ends up being the sign in front of various determinants.
minors emerging naturally. The only subtle point ends up being the sign in front of various determinants. if
if


 of cycles in
of cycles in  , saying that if
, saying that if 